Problemas de Otimização, Derivadas e o método Gradient Descent
27 de abril, 2026
No treinamento de redes neurais, temos uma função de erro que indica a diferença entre o resultado da rede e o esperado. Ao longo das iterações sobre os dados, aplica-se esta função com o objetivo de diminuir o erro através da alteração dos parâmetros da rede. Assim, é necessário um método que relacione estes parâmetros com o erro cometido, de forma que haja um ajuste de acordo com a influência que cada um teve na predição incorreta. Para isto, em redes neurais é utilizado o algoritmo
Backpropagation
, e como introdução a ele temos o método
Gradient Descent
, cuja origem vêm de uma solução para problemas de otimização.
Problemas de otimização consistem da minimização ou maximização do resultado de uma função. Por exemplo, considerando a função
, podemos calcular para qual valor
temos um valor mínimo
. Uma técnica utilizada para isto é o cálculo da derivada, que nos fornece dados sobre a inclinação da função num ponto
. Considerando que num ponto mínimo a inclinação é zero, incrementamos ou diminuimos o valor de
com a derivada, que quanto mais nos aproximamos do ponto mínimo, menor seu valor.
Um aspecto importante da derivada é o seu sinal, que quando positivo indica que o ponto está numa parte crescente da função, e se negativo, está numa parte decrescente, o que no primeiro caso indica que para minimizarmos a função devemos diminuir o valor de
, e no segundo caso aumentar, já que o objetivo é alcançar o ponto mais baixo. Desta forma, observamos que para o problema de minimização, o sinal inverso da derivada deve ser utilizado para o ajuste da variável.
Na Imagem 1, temos uma função onde
é seu ponto mínimo. Ao aplicarmos o nosso conhecimento sobre a derivada no ponto
, podemos obter o próximo valor de
em
, e enfim chegar no ponto mínimo
.
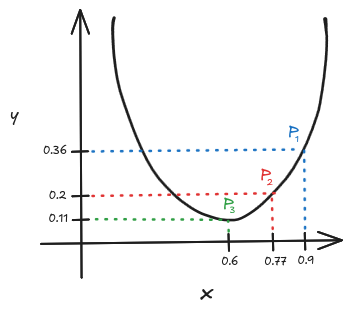
Imagem 1. Uso da derivada para minimização de uma função
No Gráfico 1, apresenta-se uma função
parecida com a da Imagem 1 e sua derivada
. Também adiciona-se uma reta tangente ao ponto
, cuja inclinação equivale à derivada
, auxiliando sua visualização no gráfico. Podemos observar que em pontos no qual a função decresce, o sinal da derivada é negativo, e em pontos que a função cresce, o sinal é positivo, e que conforme nos aproximamos do ponto mínimo [-0.5, 0.75], o valor da derivada aproxima-se de zero e diminui-se a inclinação da reta tangente.
f(1.0) = 3.00
f ' (1.0) = 3.00
f(x) = x² + x + 1
f ' (x) = 2x + 1
Gráfico 1. Visualização do cenário de minimização de uma função f(x)
No caso da função apresentar mais de uma variável, como em
, devemos calcular as derivadas de cada uma utilizando as chamadas derivadas parciais, onde calculamos a derivada de uma variável considerando as outras como constantes. Por exemplo, em
, a derivada parcial de
é dada por
, e de
,
. Nisto, um vetor composto pelas derivadas parciais desta função é chamado de
gradiente
, denotado da seguinte maneira
.
Assim como na função com uma variável, as derivadas no gradiente podem ser utilizadas para ajustar as variáveis
e
com o objetivo de minimizar a função
. Considerando o gradiente
e um vetor
com o valor das variáveis, o ajuste pode ser escrito como
, onde o sinal negativo inverte os sinais das derivadas, aplicando o comportamento que vimos de minimização da função. Na Equação 1 apresenta-se os ajustes realizados para cada variável.
Equação 1. Ajuste das variáveis da função z com os valores do gradiente
No Gráfico 2, apresenta-se uma outra função
com duas variáveis
e
, que nos permite observar como um conjunto de derivadas nos auxilia a minimizar uma função multivariável, da mesma forma que no Gráfico 1, onde tinhamos uma variável e uma derivada. Dado um ponto
, calculamos as derivadas parciais
e
, e construimos um gradiente
para minimizar
. Diferentemente da função anterior
, as derivadas parciais desta nova função
são mais complexas por causa de algumas
regras de derivação.
Para visualizarmos o gradiente, utilizamos um
vetor de posiçãona dimensão das variáveis da função, que neste caso consiste de um vetor no plano
. No gráfico, representa-se este vetor através de uma seta verde com origem no ponto
, que aponta para a direção do ponto
, que corresponde ao resultado do ajuste de
utilizando
. Ao lado do gráfico, temos este vetor num plano
com origem no ponto
e destino em
, dando ênfase à
intensidadedo vetor, ou seja, destacando a intensidade do ajuste do gradiente.
Uso do gradiente no Perceptron
Considerando um
Perceptroncom dois parâmetros, temos que sua equação ou produto escalar
é dado por
onde
. Devido à utilização da função Sinal como função de ativação, apresentada na Equação 2, o Perceptron tem como resultado os valores 1 ou -1. Disto, dado um conjunto de dados para predição neste mesmo domínio, tendo em vista que uma predição errada como 1 ao invés de -1 pode ser tratada através da diminuição do produto escalar
de forma que a função Sinal chegue à condição
, podemos abordar o treinamento do Perceptron como um problema de otimização, onde para este erro desejamos minimizar o produto escalar, e para o erro de -1 ao invés de 1, desejamos maximizá-lo.
Equação 2. Função sinal
Assim, é possível treinarmos este Perceptron através do cálculo de gradientes para o ajuste de seus parâmetros, e para isto temos o método
Gradient Descent
. Nele, define-se a atualização dos pesos para minimização e maximização de
como na Equação 3, onde
representa o vetor de pesos
, e
o gradiente da equação do Perceptron, escrito pelo vetor
, que após a resolução das derivadas parciais resulta em
. Por último tem-se o parâmetro
chamado de
learning rate
, implementado com o propósito de controlar a intensidade da atualização dos pesos através de uma taxa, geralmente definida em
. Observa-se que se este parâmetro é configurado com um valor muito alto ou baixo, corre-se o risco do gradiente ultrapassar pontos mínimos ou prender-se em um ponto mínimo insatisfatório, impedindo o treinamento do Perceptron.
Equação 3. Método Gradient Descent para minimização e maximização de z
Na Equação 4 temos a substituição dos símbolos na Equação 3 pelos dados do Perceptron para o caso de minimização, seguido das expressões para atualização dos dois parâmetros. Nota-se que em
Deep Learning, Perceptron e a operação NAND, aplicamos esta mesma fórmula para atualizarmos os pesos, ou seja, usamos o método
Gradient Descent
para treinar o Perceptron na operação NAND.
Equação 4. Gradient Descent para os parâmetros do Perceptron
No Gráfico 3, podemos simular o processo de treinamento de um Perceptron com o método
Gradient Descent
. O gráfico representa a função do Perceptron
, em que dados os valores dos pesos e o
bias
igual a 1, temos um
hiperplanoformado a partir dos valores de entrada,
e
, e o resultado da função
. Disto, a região em azul do hiperplano indica para quais entradas
temos o resultado 1 da função Sinal, e em vermelho o resultado -1, visivelmente separados pela condição
ao observarmos o eixo
.
Para configuração da simulação, primeiro deve-se definir o hiperplano do Perceptron através dos pesos
,
e
, e escolher valores para
e
, de modo que se crie uma instância de treinamento que o Perceptron erra, configurando o resultado desejado para 1 ou -1 (utilizando o botão "⟳") dependendo do que for predito. Assim, podemos simular o treinamento do Perceptron para o acerto da instância com a opção de executar o método
Gradient Descent
uma vez, ou até que o Perceptron acerte a predição. Durante este processo, conseguimos acompanhar os valores do gradiente e como acontecerá o ajuste dos pesos, bem como experimentar valores de
learning rate
e redefinir o número de execuções do método entre simulações.
Conclusão
Neste artigo vimos sobre problemas de otimização, como minimizar uma função com o uso de derivadas, e visualizações 2D e 3D deste desafio. Também relacionamos isto com o treinamento do Perceptron através do método
Gradient Descent
, finalizando com um gráfico que faz a simulação deste treinamento para uma instância. Como próximo passo temos o estudo do algoritmo
Backpropagation
, que de certa forma aplica o método
Gradient Descent
sobre toda a rede neural.
Referências
- Ekman, M. Learning Deep Learning. Pearson Education, 2021.