Deep Learning, Perceptron e a operação NAND
26 de março, 2026
Em Inteligência Artificial, temos modelos de Aprendizado de Máquina que se enquadram na área de
Deep Learning (DL)
. Nela, os modelos utilizam os chamados neurônios artificiais, que fazem parte de diversas camadas que conectam-se entre si para formação de uma
Rede Neural
.
Uma rede pode ser treinada sobre um conjunto de dados para realizar diferentes tarefas, e para isto, possui parâmetros em cada neurônio chamados de pesos, que durante o processo de treinamento são ajustados para que a rede, ao receber um dado de entrada, produza uma saída que aproxime-se do resultado esperado.
Como exemplo, na Imagem 1 ilustra-se uma rede neural com 3 camadas. Primeiro tem-se a camada de entrada que é responsável por conter os dados de entrada e disponibilizá-los para rede, em seguida uma segunda camada chamada de camada oculta, que efetivamente realiza operações sobre os dados, e a camada de saída que faz operações com o intuito de produzir o resultado desejado. Observa-se que em Deep Learning as redes neurais possuem várias camadas ocultas.
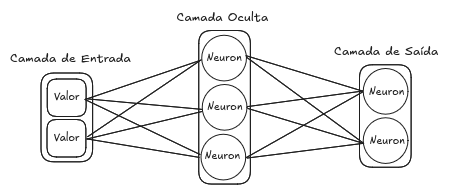
Imagem 1. Ilustração de uma Rede Neural
Esta rede neural é classificada como uma rede totalmente conexa, por todos neurônios de uma camada receber como entrada a saída de todos neurônios da camada anterior. Na imagem temos que um neurônio da camada oculta recebe todos os valores da camada de entrada, processa-os, e envia seu resultado para todos neurônios da camada de saída.
Tratando-se do processamento realizado por um neurônio, primeiro é feito o produto escalar entre os dados de entrada e os pesos do neurônio (tem-se um peso para cada valor), e em seguida aplica-se uma função sobre o resultado, chamada de
Função de Ativação
.
No código e imagem abaixo demonstra-se este processamento para um neurônio da camada oculta na Imagem 1.
Erro ao copiar
import numpy as np
# Função escolhida apenas para ilustração
def activation_function(x):
return 2 * x + 1
input = [1.2, 3.3]
weights = [0.25, -0.1]
z = np.dot(input, weights) # Produto Escalar (Dot Product)
# z = 1.2 * 0.25 + 3.3 * -0.1
# z = -0.03
output = activation_function(z) # Função de Ativação
# output = 2 * -0.03 + 1
# output = 0.94Código 1. Processamento de um neurônio em Python
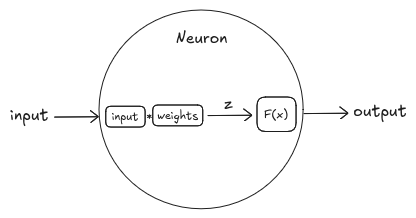
Imagem 2. Processamento de um neurônio
O
Perceptron
é uma implementação de neurônio artificial, e se caracteriza por possuir uma constante chamada
bias
com valor 1, como parte de sua entrada, e utilizar a função Sinal como função de ativação. Com base nestas especificações, modifica-se o Código 1 da seguinte forma.
Erro ao copiar
import numpy as np
# Função Sinal
def signum_activation_function(x):
if x >= 0:
return 1
else:
return -1
input = [1, 1.2, 3.3] # bias: 1
weights = [0.4, 0.25, -0.1] # Peso correspondente ao bias: 0.4
z = np.dot(input, weights) # Produto Escalar (Dot Product)
# z = 1 * 0.4 + 1.2 * 0.25 + 3.3 * -0.1
# z = 0.37
output = signum_activation_function(z) # Função de Ativação
# output = 0.37 >= 0
# output = 1Código 2. Implementação de um Perceptron
Nota-se que a alteração na função de ativação faz com que tenhamos apenas dois valores possíveis de saída (1 e -1). A adição do
bias
com seu respectivo peso, cria um parâmetro que amplia a capacidade de ajuste dos neurônios aos dados de treinamento. Pode-se imaginar que ele faz um papel similar ao parâmetro
na equação linear
, que possibilita a mobilidade da função em relação ao eixo
. Na Imagem 3 ilustra-se este comportamento.
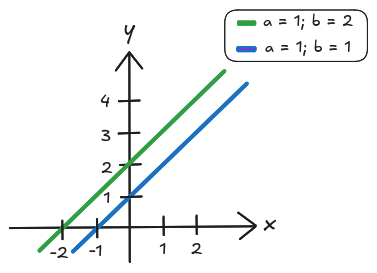
Imagem 3. Efeito da mudança do parâmetro b na função linear y = ax + b
Treinamento de um Perceptron Para Operação NAND
Uma rede neural começa com seus pesos inicializados aleatoriamente, geralmente num intervalo [-1, 1], e dado um conjunto de treinamento, treina-se a rede várias vezes sobre estes dados, cada vez numa ordem de instâncias aleatória, até que tenha um desempenho aceitável ou seja interrompido por alguma condição de parada.
O número de iterações sobre o conjunto é chamado de
epochs
, e durante o processo de treinamento ocorre a atualização dos pesos dos neurônios. Esta atualização é feita de acordo com a margem de erro do modelo, calculada considerando o resultado obtido e o resultado esperado, e a modificação dos pesos pode ocorrer a cada execução de instância do conjunto, ou após um determinado número de instâncias.
Mantendo-se o escopo sobre o funcionamento do Perceptron, podemos realizar um experimento de treinamento de um único neurônio. Neste caso, vamos treinar um Perceptron para realizar a operação NAND, que consiste da negação da operação AND entre dois valores booleanos. Na imagem abaixo mostra-se o resultado da operação para cada combinação de valores.
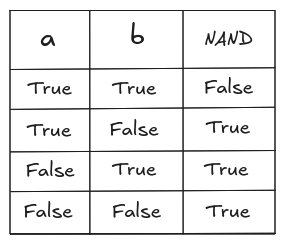
Imagem 4. Operação NAND
Considerando que o Perceptron retorna apenas os valores 1 e -1, podemos utilizar 1 para True e -1 para False, e construir o conjunto de treinamento da seguinte forma.
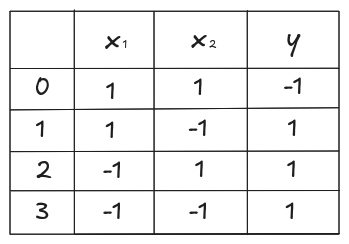
Imagem 5. Conjunto de Treinamento para operação NAND
No processo de treinamento, dado como entrada um vetor
com dois elementos, o resultado da predição deve ser compararado com o resultado esperado
, e conforme o erro cometido deve-se atualizar os pesos de forma que aproxime-se do resultado correto.
Em redes neurais utiliza-se os algoritmos
Gradient Descent
e
Backpropagation
para atualização dos pesos do modelo, introduzindo-se também a constante
learning rate
que define o tamanho do passo em que estes pesos são atualizados. Estes algoritmos levam em consideração problemas e arquiteturas complexas, e por isso utilizaremos no experimento um algoritmo mais simples.
Considerando que o objetivo do processo de treinamento é aprender a associar os dados de entrada à saída desejada, no algoritmo inclui-se os dados de entrada. Também, para controlar a intensidade em que mudam-se os valores dos pesos, seja na direção positiva ou negativa, utiliza-se a constante
learning rate
. Por fim, precisa-se de uma lógica que diminua o erro conforme o treinamento, e para isto vamos estabelecer que se o resultado é 1 e o valor esperado -1, devemos atualizar os pesos negativamente, e caso contrário, positivamente.
Lembrando que a função Sinal implementa a condição
para retornar 1, e -1 caso contrário, através do direcionamento da atualização dos pesos, influenciamos o resultado do produto escalar e consequentemente o resultado da função de ativação. Desta forma, com o aumento ou diminuição dos pesos, adaptamos o modelo para produção de um valor maior ou menor que 0, resultando em 1 ou -1 conforme desejado. Abaixo tem-se a implementação do algoritmo.
Erro ao copiar
input = [1, 1.2, 3.3]
weights = [0.4, 0.25, -0.1]
learning_rate = 0.1
correct_predictions = 0
# Exemplo de erro
output = 1
y = -1
if output != y:
for i in range(len(weights)):
weights[i] += input[i] * learning_rate * y
# Utiliza-se a propriedade de que y nos dá
# a direção que deve ocorrer a atualização:
# Se output = 1 e y = -1, então deve-se decrementar os pesos,
# ou seja, a direção deve ser negativa:
# Para i = 1, weights[1] += input[1] * 0.1 * -1
# weights[1] += 1.2 * 0.1 * -1
# weights[1] += -0.12
# Ou weights[1] = weights[1] - 0.12
# Se output = -1 e y = 1, deve-se incrementar os pesos,
# ou seja, a direção deve ser positiva:
# Para i = 1, weights[1] += input[1] * 0.1 * 1
# weights[1] += 1.2 * 0.1 * 1
# weights[1] += 0.12
# Ou weights[1] = weights[1] + 0.12
else:
correct_predictions += 1Código 3. Algoritmo simples para atualização dos pesos
Completando-se o código do experimento, para iteração sobre o conjunto de treinamento, implementa-se um
for
sobre o número de
epochs
definido, aleatorizando-se a ordem dos dados a cada
epoch
. A cada iteração completa sobre o conjunto, verifica-se o número de instâncias preditas corretamente, e interrompe-se a execução caso acerte todas. Abaixo apresenta-se o esqueleto deste processo.
Erro ao copiar
for epoch in range(epochs):
random.shuffle(index_instances)
correct_predictions = 0
for idx in index_instances:
...
if output != y:
...
else:
correct_predictions += 1
if correct_predictions == len(data):
break Código 4. Processo de treinamento do Perceptron
Abaixo exibe-se o código completo do experimento, incluindo o treinamento e teste do Perceptron para operação NAND.
Erro ao copiar
import numpy as np
import random
random.seed(7)
num_weights = 3
interval = [-1, 1]
weights = [random.uniform(interval[0], interval[1]) for _ in range(num_weights)]
# x1, x2, y
data = [[-1, 1, 1],
[-1, -1, 1],
[1, -1, 1],
[1, 1, -1]]
index_instances = [0, 1, 2, 3]
learning_rate = 0.1
epochs = 50
# Treinamento
for epoch in range(epochs):
random.shuffle(index_instances)
correct_predictions = 0
for idx in index_instances:
input = data[idx].copy()
y = input[-1]
# Bias
input.insert(0, 1)
# input[:3] -> bias, x1, x2
z = np.dot(input[:3], weights)
# Função Sinal
output = 1 if z >= 0 else -1
if output != y:
for i in range(len(weights)):
weights[i] += input[i] * learning_rate * y
else:
correct_predictions += 1
if correct_predictions == len(data):
break
# Teste
for instance in data:
instance.insert(0, 1)
z = np.dot(instance[:3], weights)
output = 1 if z >= 0 else -1
print(f"x1 = {instance[1]}, x2 = {instance[2]}, y = {instance[3]}, output = {output}")Código 5. Treinamento e teste de um Perceptron para realização da operação NAND
Conclusão
Neste artigo vimos conceitos gerais sobre redes neurais e neurônios artificiais. Estudamos a implementação do Perceptron e o utilizamos para realizar a operação lógica NAND. Com isto, temos uma introdução sobre um dos componentes de uma rede neural, e para complementar este artigo, em
Mais Sobre o Perceptron e Bias, vemos mais pontos interessantes sobre o Perceptron.
Referências
- Ekman, M. Learning Deep Learning. Pearson Education, 2021.