Predição de várias classes e o dataset MNIST
29 de maio, 2026
Em
Backpropagation e a operação lógica XOR [2/2], implementamos uma rede neural para predição de duas classes, 1 e -1, utilizando um neurônio na camada de saída. No código, tinhamos o resultado 1 com a condição
, e -1 se
, com
sendo o resultado da função de ativação, e
threshold
o valor mediano do contradomínio da função escolhida. Disto, para implementação da predição de
classes com
, temos que são necessários
neurônios na camada de saída, e uma função de erro que suporta a comparação entre resultados com
valores.
Um conjunto de dados que possui várias classes é o
dataset
MNIST
(
Modified National Institute of Standards and Technology
), que disponibiliza 70.000 imagens de dígitos de 0 a 9, escritos à mão, em escala de cinza e com dimensões 28x28. Cada imagem tem uma anotação de qual dígito ela representa, possibilitando a construção de uma rede que recebe como entrada 784 valores (28x28) de 0 a 255 de uma imagem, e produz como resultado qual dígito de 0 a 9 ela mais se assemelha. Na Imagem 1, ilustra-se um exemplo de uma imagem do dígito 7 no
dataset
MNIST, e a transformação de seus dados para entrada na rede.
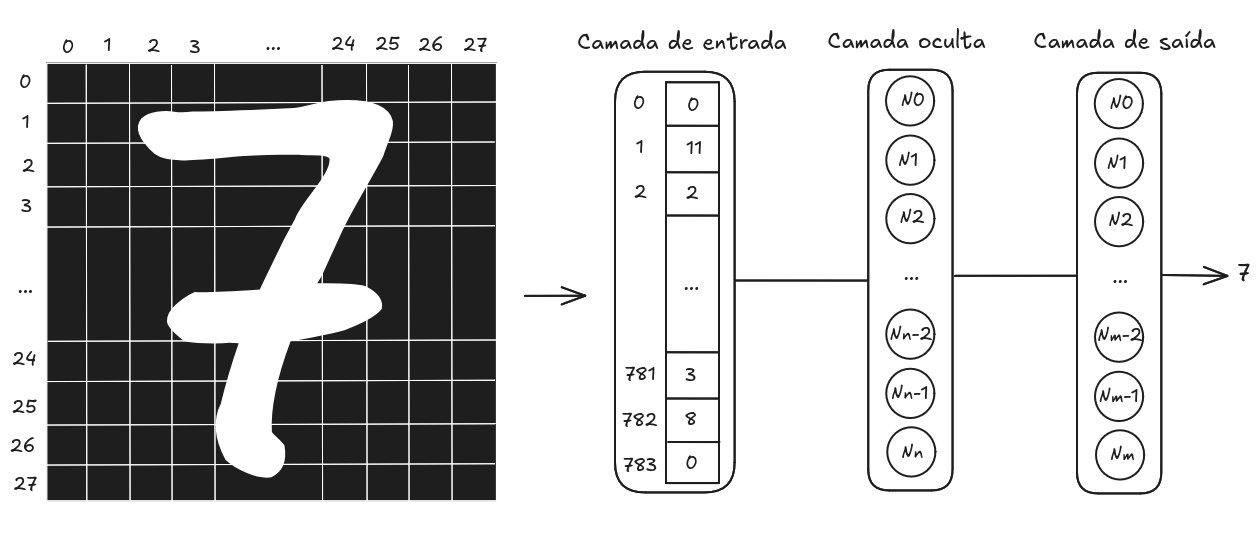
Imagem 1. Exemplo de uma imagem no dataset MNIST e formato de entrada na rede neural
Considerando que temos dez dígitos para classificação, a rede precisa de dez neurônios na camada de saída, cada um responsável pela predição de um dígito. Disto, a saída correta da rede para uma classe é um conjunto de valores em que o resultado do neurônio dessa classe se destaca dos demais. Com isto em mente, podemos utilizar a técnica
one-hot encoding
para definição do resultado esperado de uma imagem, como um conjunto de dez valores em que a posição
do dígito alvo tem valor 1, e o restante valor 0. Na Imagem 2, exibe-se em
um resultado correto da rede para respectiva entrada, onde a saída do neurônio
se destaca, e em
mostra-se o
encoding
do resultado esperado.
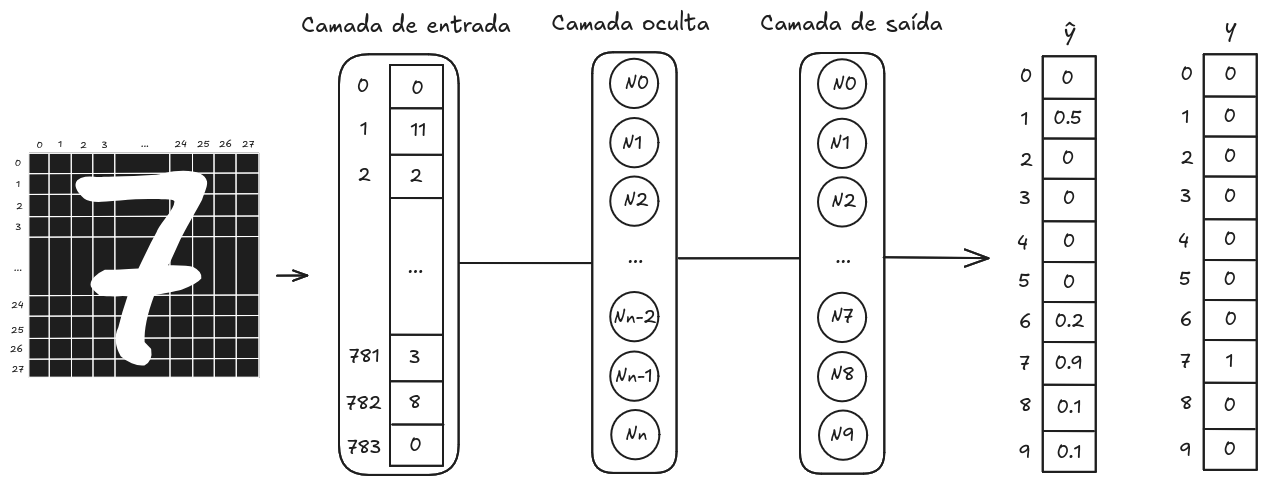
Imagem 2. Exemplo de um resultado correto da rede e o encoding do resultado esperado
No treinamento da rede, dada a imagem de um dígito, será feito com que o neurônio correspondente tenha um resultado maior do que os outros, próximo de 1, e os demais, valores próximos de 0. Observa-se que podemos utilizar a função Logística como função de ativação, por seu contradomínio estar no intervalo [0, 1], e que a função de erro da rede deve fazer a comparação de cada valor do
encoding
com os resultados dos neurônios para o cálculo do erro. Uma função que podemos usar é exibida na Equação 1, no qual fazemos a soma do erro
de cada neurônio
, onde
e
são seus respectivos valor esperado e resultado da função de ativação. Em um
artigo anterior, vimos que
vem da métrica
Mean Squared Error
.
Equação 1. Função de erro da rede para treinamento no dataset MNIST
Lembrando-se do algoritmo
Backpropagation
, o processo de minimização da função de erro fará esta aproximação dos resultados dos neurônios aos valores do
encoding
, por isto conduzir a um erro menor. No Quadro 1, mostra-se o cálculo do erro para uma saída
próxima e outra distinta do resultado esperado
.
Quadro 1. Cálculo do erro para um resultado próximo e distinto do encoding
Devido à camada de saída possuir mais de um neurônio, as derivadas parciais dos parâmetros da rede contém a soma das derivadas do erro de cada um. Considerando a rede na Imagem 3, as derivadas parciais dos pesos de
são exibidas no Quadro 2. No Quadro 3 apresenta-se a resolução das derivadas parciais do erro em relação às funções de ativação dos neurônios da camada de saída. Nos cálculos, exceto a variável da função em questão, as outras são consideradas como constantes, resumindo a expressão de
, por exemplo, para o cálculo de
, que resulta em
, como vimos em
Backpropagation e a operação lógica XOR [1/2]. No Quadro 4 mostra-se os resultados das derivadas dos parâmetros de
.
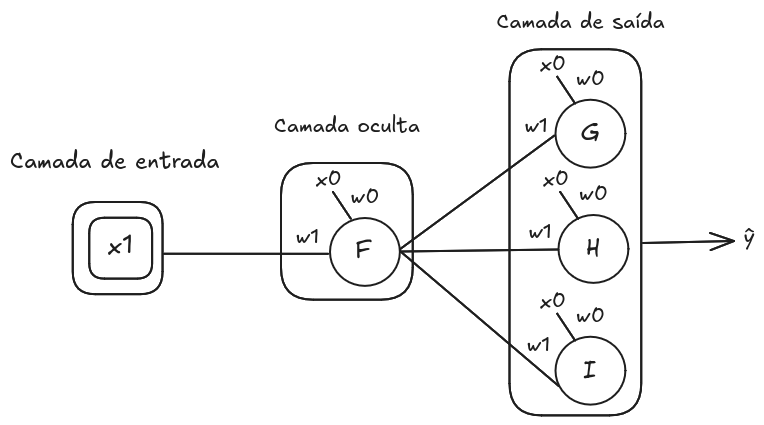
Imagem 3. Rede neural com uma camada de saída com mais de um neurônio
Quadro 2. Derivadas parciais do neurônio F na Imagem 3
Quadro 3. Resolução das derivadas parciais da função de erro em relação às funções de ativação de G, H e I
Quadro 4. Resolução das derivadas parciais de F
Implementação da rede para treinamento e teste no dataset MNIST
Para obtermos o
dataset
, podemos utilizar a biblioteca
como no Código 1. Em
e
, divide-se o conjunto em 60.000 imagens para treinamento e 10.000 para teste, tendo-se em
e
as anotações dos dígitos.
Erro ao copiar
import keras
from keras.datasets import mnist
(train_X, train_y), (test_X, test_y) = mnist.load_data()Código 1. Obtenção do dataset
Utilizaremos como base a
implementaçãoda rede que fizemos para operação XOR. Primeiro, no Código 2 exibe-se o treinamento da rede, onde utilizamos uma lista de índices aleatorizada do conjunto para acessar os dados a cada
epoch
, e enviamos cada imagem em
na forma de matriz, e sua anotação em
, para processamento na rede. Disto, calcula-se a acurácia do treinamento com a função
da biblioteca
, modificando a ordem das anotações de acordo com a aleatorização dos índices, para comparação com os resultados em
.
Erro ao copiar
index_list = np.arange(train_data_X.shape[0]).tolist()
for epoch in range(epochs):
correct_train = 0
np.random.shuffle(index_list)
network.train_mode()
train_y_pred = []
for i in index_list:
train_output = network.process(train_X[i], train_y[i])
train_y_pred.append(train_output)
shuffled_train_data_y = train_y[index_list]
train_accuracy = accuracy_score(shuffled_train_data_y, train_y_pred)Código 2. Treinamento da rede
No caso da operação XOR, a função
da classe
enviava os dados de entrada para primeira camada sem alterá-los, e o valor esperado
continha apenas um valor numérico. Para o
dataset
MNIST, modificamos esta função como no Código 3, onde transformamos a matriz da imagem em uma lista de 784 números com a função
, e criamos o
encoding
do resultado esperado utilizando a anotação do dígito como valor da posição do valor 1 em
.
Erro ao copiar
def process(self, data_X, data_y):
output = self.forward_pass(data_X.flatten())
if self.is_inf_mode:
return output
y = np.zeros(10)
y[data_y] = 1
if output != data_y:
self.backward_pass(y)
return outputCódigo 3. Modificação da função process de NeuralNetwork
No Código 4, alteramos as funções
e
da camada de saída em
para suportar mais de um neurônio. Em específico, na função
definimos o resultado
da rede através da função
, que retorna o índice do maior valor na lista de resultados dos neurônios. Na função
, começa-se a propagação do erro a partir de cada neurônio, iniciando na rede a sequência de somas que vimos no cenário da Imagem 3. Nota-se que para o cálculo do erro dos neurônios, envia-se o resultado esperado
correspondente.
Erro ao copiar
def process(self, input):
output = []
for neuron in self.list_neurons:
neuron.process(input)
output.append(neuron.output)
self.output = np.array(output).argmax()
def update(self, y, learning_rate):
prop_error = None
for i, neuron in enumerate(self.list_neurons):
error = neuron.update(learning_rate=learning_rate, y=y[i])
if prop_error is None:
prop_error = np.zeros(len(error))
prop_error += error
self.previous_layer.update(learning_rate, prop_error)Código 4. Alteração das funções process e update de OutputLayer
No Código 5, exibe-se o teste da rede realizado a cada
epoch
.
Erro ao copiar
network.inf_mode()
test_y_pred = []
for j in range(test_X.shape[0]):
test_output = network.process(test_X[j], test_y[j], show_output=False)
test_y_pred.append(test_output)
test_accuracy = accuracy_score(test_y, test_y_pred)Código 5. Teste da rede
Experimentos de configurações da rede no dataset MNIST
Com uma camada de entrada com 784 valores de 0 a 255, e uma camada de saída com 10 neurônios utilizando a função Logística, foram feitos experimentos variando o número de camadas ocultas com a função Tangente, e o número de neurônios em cada uma. Para avaliação dos experimentos, utilizou-se a biblioteca
para registrar os dados de cada execução da rede, incluindo a configuração das camadas e a acurácia no treinamento e teste a cada
epoch
, como mostra-se no Código 6.
Erro ao copiar
import mlflow
from mlflow import MlflowClient
# Armazenamento dos dados em um banco local
mlflow.set_tracking_uri("sqlite:///mlflow.db")
mlflow.set_experiment("mnist")
# Configuração da rede
...
# Para registro da configuração das camadas ocultas
hidden_layers_spec = {
f"hidden_layer_{i}": {
"num_neurons": network.hidden_layers[i].num_neurons,
"act_function": network.hidden_layers[i].act_function
}
for i in range(network.num_hidden_layers)
}
...
with mlflow.start_run() as run:
# Para registro da configuração da rede
params = {
"num_hidden_layers": network.num_hidden_layers,
"hidden_layers_spec": hidden_layers_spec,
"output_layer_spec": {
"num_neurons": network.output_layer.num_neurons,
"act_function": network.output_layer.act_function
},
"learning_rate": network.learning_rate,
"epochs": epochs
}
mlflow.log_params(params)
for epoch in range(epochs):
...
# Para registro da acurácia no treino e teste a cada epoch
mlflow.log_metrics({f"train_accuracy": train_accuracy, f"test_accuracy": test_accuracy}, step=epoch)Código 6. Uso da biblioteca MLflow para registro dos dados dos experimentos
No Código 7 apresenta-se o uso da biblioteca para recuperação destas informações.
Erro ao copiar
mlflow_client = MlflowClient()
experiment = mlflow_client.get_experiment_by_name("mnist")
experiment_id = experiment.experiment_id
runs = mlflow_client.search_runs(experiment_ids=[experiment_id])
for run in runs:
print(f"\nRun ID: {run.info.run_id}")
print(f"Status: {run.info.status}")
print("Configuração:")
for param, value in run.data.params.items():
print(f" - {param}: {value}")
print("Acurácia:")
train_acc_metrics = mlflow_client.get_metric_history(run.info.run_id, "train_accuracy")
print("Treinamento:")
for train_metric in train_acc_metrics:
print(f"{train_metric.value}, ", end="")
test_acc_metrics = mlflow_client.get_metric_history(run.info.run_id, "test_accuracy")
print("\nTeste:")
for test_metric in test_acc_metrics:
print(f"{test_metric.value}, ", end="")Código 7. Recuperação dos dados dos experimentos
Para agilizar o teste de cada versão da rede, foram selecionados para os experimentos um subconjunto de 1.000 instâncias para treinamento e 200 para teste, como mostra-se no Código 8. Disto, optou-se pela definição de um número considerável de
epochs
para avaliar a capacidade de aprendizado das mesmas, começando-se com 200.
Erro ao copiar
train_X_subset = []
train_y_subset = []
test_X_subset = []
test_y_subset = []
for i in range(10):
digit_i_subset_train_X = train_data_X[train_data_y == i]
digit_i_subset_train_y = train_data_y[train_data_y == i]
train_X_subset.extend(digit_i_subset_train_X[:100])
train_y_subset.extend(digit_i_subset_train_y[:100])
digit_i_subset_test_X = test_data_X[test_data_y == i]
digit_i_subset_test_y = test_data_y[test_data_y == i]
test_X_subset.extend(digit_i_subset_test_X[:20])
test_y_subset.extend(digit_i_subset_test_y[:20])
train_X_subset = np.asarray(train_X_subset)
train_y_subset = np.asarray(train_y_subset)
test_X_subset = np.asarray(test_X_subset)
test_y_subset = np.asarray(test_y_subset)Código 8. Processo de seleção dos subconjuntos de dados para os experimentos
Como primeiro experimento, utilizou-se uma única camada oculta com 10, 25, 50, 75 e 100 neurônios. No Gráfico 1 mostra-se os resultados, e na Tabela 1 apresenta-se a maior acurácia de cada configuração no conjunto de teste, seguida da
epoch
em que foi obtida.
Gráfico 1. Experimento com uma camada oculta e número de neurônios variado
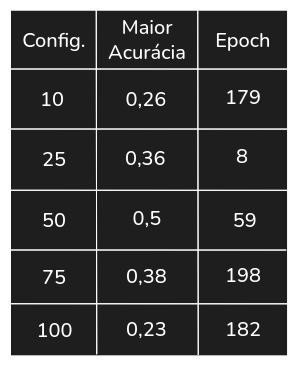
Tabela 1. Maiores acurácias no conjunto de teste no Experimento 1
Observa-se que os resultados não são muito promissores, com a maior acurácia no conjunto de teste sendo de 0,5 para a rede com 50 neurônios. Mesmo assim, nota-se que esta versão obteve resultados visivelmente superiores às outras, também tivemos um aumento crescente da acurácia da rede com 75 neurônios ao longo das
epochs
, e o desempenho com 100 neurônios foi semelhante aos das versões com 10 e 25 neurônios.
Por causa do crescimento da acurácia com 75, no segundo experimento executamos estas mesmas configurações com 300
epochs
, para verificar se a rede continuaria a melhorar e se as outras também iriam começar a exibir este comportamento. No Gráfico 2 apresenta-se os resultados, e na Tabela 2 temos as maiores acurácias de cada rede na fase de teste.
Gráfico 2. Aumento do número de epochs para treinamento no Experimento 1
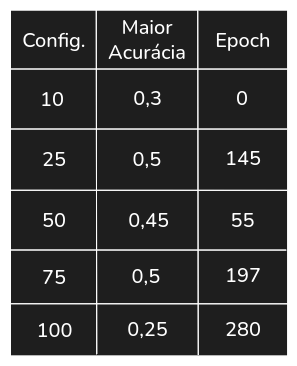
Tabela 2. Maiores acurácias no conjunto de teste no Experimento 2
Observamos que nesta execução, a rede com 25 neurônios equiparou-se à rede com 50, e que a versão com 75 neurônios alcançou o desempenho destas duas redes no conjunto de teste, obtendo resultados no conjunto de treinamento na faixa de 0,6 de acurácia. Nota-se que esta diferença de desempenho no treino e teste pode indicar o começo de um
overfittingda rede, onde ajustamos seus parâmetros especificamente para predição correta dos dados de treinamento, em detrimento da obtenção de parâmetros que também desempenhem bem em dados alheios, os dados de teste, não alcançando uma solução
generalizada.
Com o intuito de obter melhores resultados, no terceiro experimento adicionou-se uma segunda camada oculta nas redes com 25, 50 e 75 neurônios, que tiveram os melhores desempenhos nos experimentos anteriores. Nesta segunda camada de cada rede foi colocado o mesmo número de neurônios da primeira camada, adotando-se a notação 25-25, 50-50 e 75-75 para as novas configurações, e continuou-se com 300
epochs
. No Gráfico 3 exibe-se os resultados, e na Tabela 3, as maiores acurácias de cada rede no conjunto de teste.
Gráfico 3. Adição de uma segunda camada oculta nas melhores configurações do Experimento 2
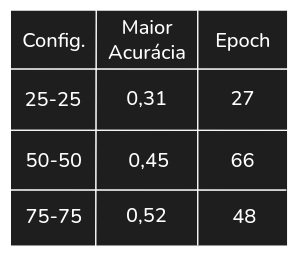
Tabela 3. Maiores acurácias no conjunto de teste no Experimento 3
Como resultado, não houveram ganhos significativos de desempenho no conjunto de teste, e as redes 50-50 e 75-75 tiveram casos acentuados de
overfitting
. No entanto, ao menos a rede 75-75 demonstrou-se capaz de se ajustar ao conjunto de treinamento, com uma acurácia de 0,82 na
epoch
221.
No quarto experimento, variou-se o número de neurônios na segunda camada da rede 75-75. Apresenta-se os resultados no Gráfico 4, e na Tabela 4 as maiores acurácias de cada rede no conjunto de teste.
Gráfico 4. Variações no número de neurônios da segunda camada da rede 75-75
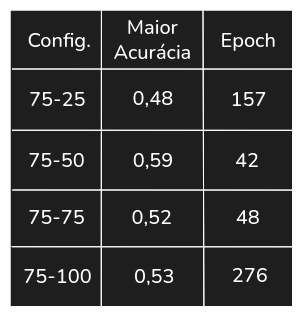
Tabela 4. Maiores acurácias no conjunto de teste no Experimento 4
Visto o avanço da acurácia para 0,59 em 75-50, como último experimento adicionou-se uma terceira camada nesta configuração com 25, 50 e 75 neurônios, criando as redes 75-50-25, 75-50-50 e 75-50-75. Observando os melhores resultados, por não terem ultrapassado o desempenho da rede 75-50, adicionou-se à melhor rede deste experimento, a rede 75-50-50, uma quarta camada com 50 e 75 neurônios. Todos resultados são apresentados no Gráfico 5, e na Tabela 5 temos as maiores acurácias de cada configuração no conjunto de teste.
Gráfico 5. Último experimento com três e quatro camadas ocultas
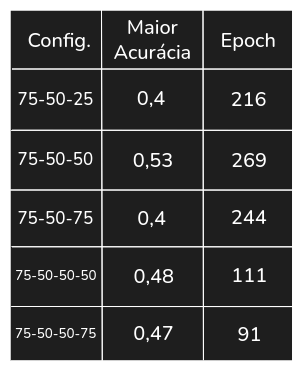
Tabela 5. Maiores acurácias no conjunto de teste no Experimento 5
Sem demais ganhos de desempenho, a configuração que obteve o melhor resultado dentre todas foi a rede 75-50. Assim, a executamos sobre todo conjunto de treinamento e teste do
dataset
MNIST, utilizando apenas 20
epochs
pela implementação da rede não ser eficiente o bastante para maiores iterações com todo conjunto. No Gráfico 6 exibe-se os resultados.
Gráfico 6. Execução da rede 75-50 com todo dataset MNIST
Em
https://gist.github.com/RenanGAS/ea3a309d4b5f84d3ba2457c76a3f403ddisponibiliza-se um Jupyter Notebook com as modificações na implementação da rede e o código utilizado nos experimentos.
Conclusão
Neste artigo vimos sobre como pode ser feita a predição de várias classes em um rede neural, e as modificações necessárias na rede da operação XOR para predição de dígitos no
dataset
MNIST. Realizamos experimentos com várias configurações de camadas ocultas, e nos deparamos com o problema de
overfitting
e um baixo desempenho em geral. Desta forma, como próximo passo temos a aplicação de técnicas para lidar com estes problemas, como a normalização dos dados, o uso de diferentes valores de
learning rate
e mudanças na inicialização dos parâmetros dos neurônios.
Referências
- Ekman, M. Learning Deep Learning. Pearson Education, 2021.
- MNIST database. Wikipedia, 2026. Disponível em: https://en.wikipedia.org/wiki/MNIST_database.
- Overfitting. Wikipedia, 2026. Disponível em: https://en.wikipedia.org/wiki/Overfitting#Machine_learning.
- Generalization error. Wikipedia, 2026. Disponível em: https://en.wikipedia.org/wiki/Generalization_error.