Uma rede neural é composta por diversas camadas, sendo a primeira a camada de entrada, que insere os dados na rede. Compondo a maior parte, temos as camadas ocultas, que contém neurônios que processam os dados de acordo com seus parâmetros e enviam seus resultados para os neurônios da camada seguinte. A última camada, chamada de camada de saída, é responsável por conter os neurônios que resultam em valores condizentes ao objetivo da predição.
Durante o processo de treinamento, a rede precisa ajustar os parâmetros dos neurônios para alcançar uma série de resultados, fazendo-se necessário uma função que quantifique o erro cometido pela rede, e um método que determine como cada neurônio deve modificar seus parâmetros para que este erro diminua.
De acordo com o tipo de predição são utilizadas diferentes
Funções de Erro
, em que no caso de valores escalares, temos por exemplo a função
Mean Squared Error
(MSE), apresentada na Equação 1. Podemos interpretar esta função como uma forma de calcular o erro médio de
instâncias, onde
é o resultado esperado, e
é a saída da rede para instância
. Disto, também podemos extrair a expressão
, como o erro para uma única instância
Equação 1. Mean Squared Error
Em
Problemas de Otimização, Derivadas e o método Gradient Descent , vimos sobre o treinamento do Perceptron utilizando o método
Gradient Descent
, aplicando o cálculo do gradiente sobre a equação
. Neste caso, fizemos isto porque formulamos o treinamento como a minimização de
para o erro em que predizemos 1 ao invés de -1, e maximização para o erro de -1 ao invés de 1. Se tivéssemos mais Perceptrons, criando uma rede com mais de uma camada, não conseguiríamos utilizar o gradiente desta maneira, pois não sabemos qual a predição correta para cada neurônio, a não ser para os que estão na camada de saída.
Assim, no treinamento é utilizado o algoritmo
Backpropagation
, que aborda o treinamento como um problema de minimização da função de erro. Disto, considerando o erro para uma instância
, precisamos definir as expressões matemáticas por trás de
, ou seja, o encadeamento de equações e funções de ativação dos neurônios, do começo ao fim da rede, que geram
. Considerando uma rede neural como na Imagem 1, a função do erro pode ser escrita como
, onde
é a expressão da rede em função dos parâmetros dos neurônios. Com isto, conseguimos aplicar o método
Gradient Descent
para minimizar esta função com o gradiente
, como mostra-se no Quadro 1, em que ajustamos os parâmetros com suas respectivas derivadas parciais em relação à função do erro.
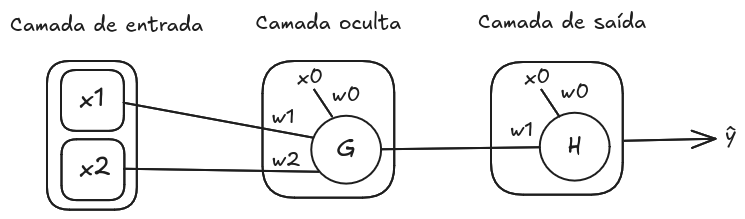
Imagem 1. Exemplo de uma rede neural com dois neurônios G e H
Quadro 1. Método Gradient Descent para minimização da função de erro
Uma detalhe é que não podemos utilizar a função Sinal como função de ativação nos neurônios, como é feito no Perceptron. De acordo com o teorema da
diferenciabilidade , uma função diferenciável é contínua em todos seus pontos, concluindo-se que não é possível o cálculo da derivada da função Sinal, por ela não ser contínua em
. No gradiente
, o cálculo das derivadas parciais depende da diferenciabilidade de
, sendo necessário o uso de funções de ativação diferenciáveis. Para isto, em redes neurais temos funções como a função Tangente e a função Logística, apresentadas na Imagem 2 junto com a função Sinal.
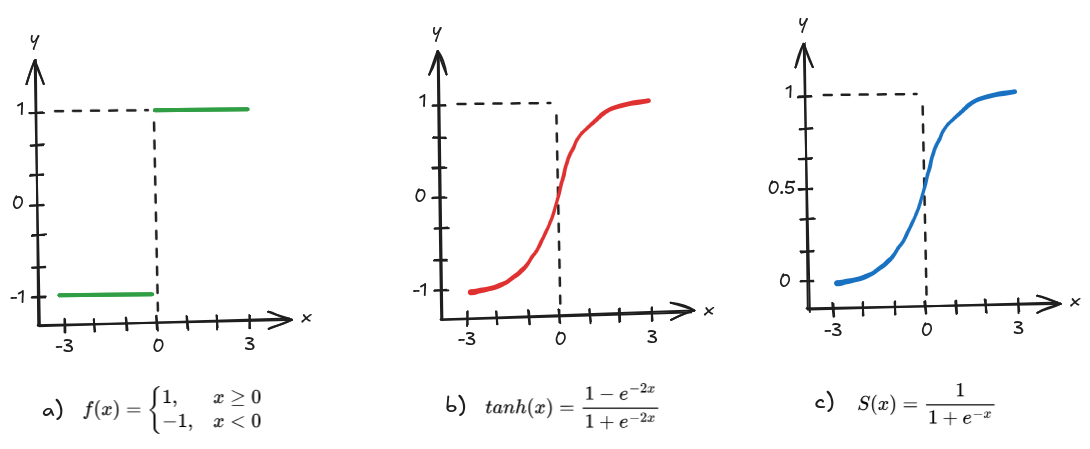
Imagem 2. a) Função Sinal, b) Função Tangente e c) Função Logística
Observa-se que estas duas funções têm um formato em "S", e que a função Tangente tem seu resultado contido no intervalo [-1, 1], e a função logística no intervalo [0, 1]. Disto, temos que geralmente utiliza-se a função Tangente nos neurônios das camadas ocultas, e a função Logística na camada de saída. A função Tangente serve como uma substituição direta da função Sinal, considerando a semelhança entre os valores máximo e mínimo, -1 e 1, de ambas funções, e a função Logística é vista como útil para a camada de saída, por seu resultado poder ser interpretado como uma probabilidade.
Considerando a rede na Imagem 1, utilizando-se a função Tangente em
e a função Logística em
, as operações realizadas por ambos neurônios são exibidas nas Equações 2 e 3, respectivamente. Observa-se que o resultado da função de ativação de
é utilizado como entrada pelo neurônio
Equação 2. Produto escalar e função de ativação do neurônio G
Equação 3. Produto escalar e função de ativação do neurônio H
Disto, retomando-se a função do erro
, dado que
representa a expressão da rede para
, que corresponde ao resultado da função de ativação do neurônio
,
, podemos substituir
por
, tendo-se
. Observa-se que a partir de
, temos uma
composição de funções , denotada na Equação 4, onde
está em função de
,
em função de
,
em função de
, e
em função de
Equação 4. Composição de funções a partir da função do erro
Para o cálculo de derivadas parciais de funções compostas, temos a
regra da cadeia apresentada na Equação 5. Nela, a derivada parcial de uma função
em relação a
, onde
está em função de
, pode ser escrita como o produto das derivadas
e
. Disto, podemos entender que de acordo com a variável alvo, definimos uma sequência de funções que se conectam com a função que a contém, e realizamos o produto de suas derivadas.
Equação 5. Regra da cadeia
Considerando os parâmetros dos neurônios
e
, no Quadro 2 temos as fórmulas para o cálculo de suas respectivas derivadas parciais em relação à função de erro.
Quadro 2. Fórmulas das derivadas parciais de H e G na Imagem 1
Tendo em vista a função composta
, para as derivadas parciais do neurônio
,
e
, aplicamos a regra da cadeia até a função
. Já para as derivadas de
,
,
e
, continuamos através de
, até alcançarmos a função
. Percebe-se que a diferença entre as derivadas parciais dos parâmetros de um neurônio é o último termo, em que fazemos a derivada do produto escalar em relação a um dos parâmetros, e que quanto mais profundo o neurônio está da última camada até a primeira, as derivadas levam em conta termos que na prática já terão sido calculados pelos neurônios anteriores, acrescentando apenas o cálculo das suas derivadas específicas, como
e
em
No Quadro 3, resolvemos os termos que compõem as derivadas parciais.
Quadro 3. Resolução dos termos das derivadas parciais no Quadro 2
Para resolução das derivadas das funções
e
, a não ser pela variável em questão, consideramos as outras como constantes, tendo como resultado o termo que é multiplicado pela variável alvo. No caso das derivadas das funções de ativação
e
, temos a propriedade de que podemos escrevê-las em função das próprias funções
e
, não sendo necessário desenvolvermos as derivadas a partir das suas equações mostradas na Imagem 2. Por fim, para resolvermos a derivada
, primeiro dividimos a equação do erro por 2 com o intuito de simplificar a expressão final, o que não terá um efeito significativo no processo de ajuste dos parâmetros. Após isto, resolvemos a derivada aplicando a regra da multiplicação por uma constante e a regra da cadeia em
, onde identificamos uma função composta
, tendo-se
e
, cujo desenvolvimento segue como
, em que aplicamos a regra da potência e calculamos uma derivada simples.
Com isto, no Quadro 4 temos os resultados das derivadas parciais dos neurônios
e
Quadro 4. Derivadas parciais dos neurônios H e G na Imagem 1
Conexões com mais de um neurônio
Uma rede neural geralmente terá mais de um neurônio por camada, ocorrendo conexões em que um neurônio envia seu resultado para
neurônios, e conexões onde
neurônios enviam seus resultados para um. Na Imagem 3 ilustra-se uma rede com um neurônio
que envia seu resultado para os neurônios
e
, e um neurônio
que recebe como entrada o resultado de ambos.
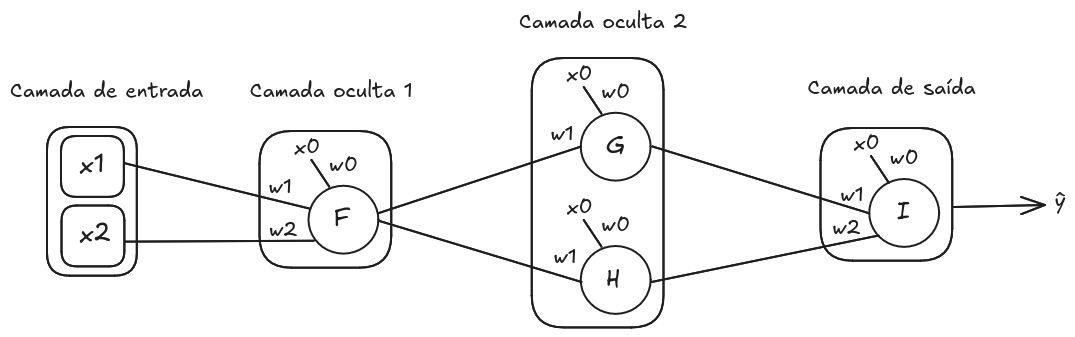
Imagem 3. Exemplo de uma rede com conexões com mais de um neurônio
Para o cálculo do gradiente da função de erro desta rede, consideramos a função composta na Equação 6. Disto, no Quadro 5 temos as fórmulas das derivadas parciais de
e
, que se diferenciam na derivada
, onde cada um utiliza a sua função de ativação. Encontra-se as expressões de
,
e
Equação 6. Função composta do erro da rede na Imagem 3
Quadro 5. Fórmulas para o cálculo das derivadas parciais de G e H
Equação 7. Produto escalar dos neurônios I, G e H
Assumindo a função Logística
para
, e a Tangente
para
e
, apresenta-se no Quadro 6 as derivadas parciais destes dois neurônios em relação à função de erro
Quadro 6. Derivadas parciais dos neurônios G e H na Imagem 3
Para o cálculo das derivadas parciais do neurônio
, devemos aplicar a
regra da cadeia para várias variáveis , definida na Equação 8. Isto, pelo fato de
ser uma função multivariável de
e
, que recebem como entrada o resultado das funções
e
, respectivamente, no qual ambas possuem como parâmetro a função
que depende de
, onde temos os parâmetros do neurônio. Destaca-se estas relações no seguinte trecho da função composta
Equação 8. Regra da cadeia para várias variáveis
Aplicando-se a regra, no Quadro 7 e 8 temos as fórmulas e as derivadas parciais de
Quadro 7. Fórmulas para o cálculo das derivadas parciais de F
Quadro 8. Derivadas parciais do neurônio F
Conclusão
Neste artigo vimos sobre o algoritmo
Backpropagation
, onde aplicamos o método
Gradient Descent
para minimizar a função de erro. Nisto, resolvemos as derivadas parciais dos parâmetros da rede através da aplicação da Regra da Cadeia sobre a função composta do erro, em que levamos em consideração as operações de todos neurônios. Disto, resta a apresentação formal do algoritmo, em que o dividimos em duas etapas chamadas de
forward pass
e
backward pass
, e uma implementação prática. Então, como continuação teremos a visão do algoritmo
Backpropagation
em etapas e seu uso para resolver a operação lógica XOR.
Referências
- Ekman, M. Learning Deep Learning. Pearson Education, 2021.
- Derivada. Wikipedia, 2026. Disponível em: https://pt.wikipedia.org/wiki/Derivada#Diferenciabilidade.
- Composição de funções. Wikipedia, 2026. Disponível em: https://pt.wikipedia.org/wiki/Composi%C3%A7%C3%A3o_de_fun%C3%A7%C3%B5es.
- Regra da cadeia. Wikipedia, 2026. Disponível em: https://pt.wikipedia.org/wiki/Regra_da_cadeia.
- Chain Rule. Paul's Online Notes, 2026. Disponível em: https://tutorial.math.lamar.edu/classes/calciii/chainrule.aspx.