Backpropagation e a operação lógica XOR [2/2]
11 de maio, 2026
Em
Backpropagation e a operação lógica XOR [1/2], vimos sobre a aplicação do método
Gradient Descent
no algoritmo
Backpropagation
, com o cálculo do gradiente para minimização da função de erro
Mean Squared Error
(MSE). Sobre o algoritmo, destaca-se também sua divisão em duas etapas, chamadas de
forward pass
e
backward pass
, que nos permite organizar os cálculos envolvidos no gradiente.
A etapa
forward pass
trata-se do processamento dos dados de entrada pela rede, onde calculamos os resultados das funções de ativação dos neurônios e o erro entre a saída e o resultado esperado. Já o
backward pass
consiste do cálculo das derivadas parciais de cada parâmetro, começando dos neurônios da camada de saída, onde utilizamos os resultados das funções de ativação. Na Imagem 1 ilustra-se estas etapas.
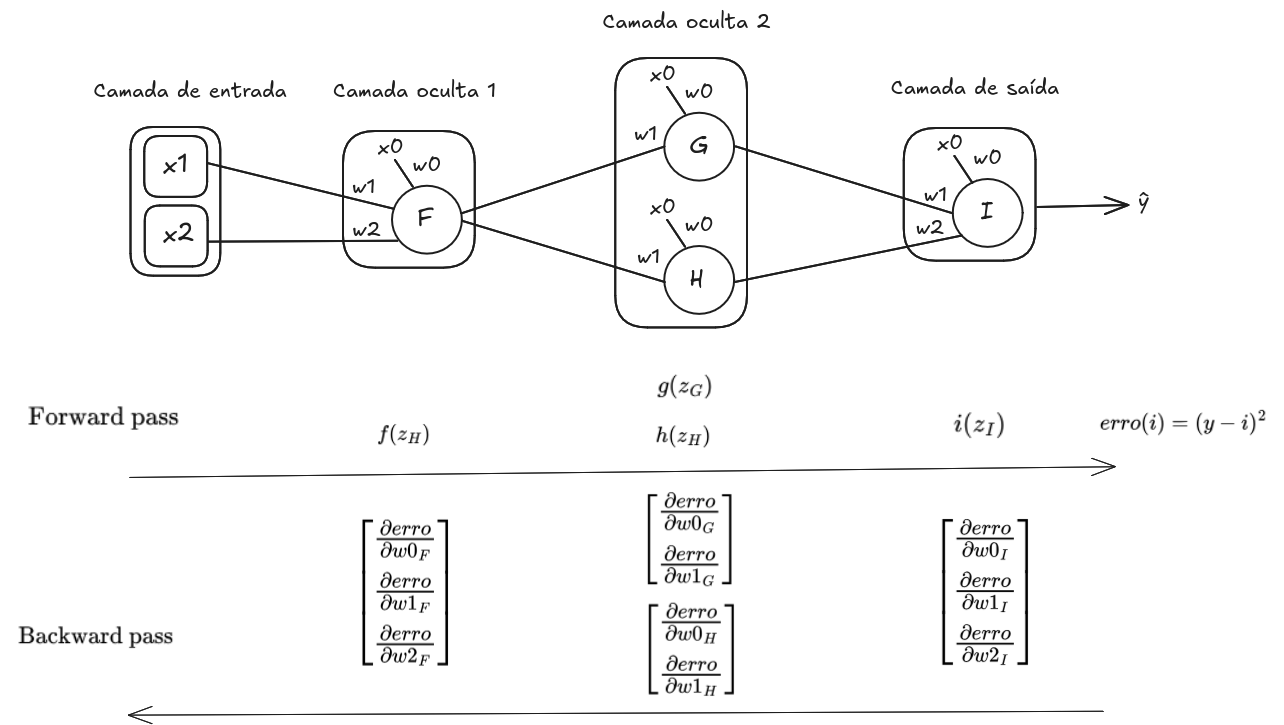
Imagem 1. Etapas forward pass e backward pass do algoritmo Backpropagation
Finalizando a segunda etapa obtemos os gradientes de cada neurônio, restando a aplicação do método
Gradient Descent
como no Quadro 1.
Quadro 1. Aplicação do método Gradient Descent utilizando os gradientes de cada neurônio
No Quadro 2, temos as derivadas parciais dos pesos
,
e
do neurônio
em relação à função de erro. Analisando estas expressões, percebemos a repetição da expressão
, que consiste da derivada da função de erro multiplicada pela derivada da função de ativação de
. Também destaca-se que nelas a expressão é multiplicada pelo dado de entrada correspondente ao peso em questão no produto escalar
.
Quadro 2. Derivadas parciais dos parâmetros de I
Do mesmo modo, no Quadro 3 observamos que nas derivadas parciais de
e
, repetem-se os termos
e
, formados a partir da expressão que vimos em
, multiplicada pelo parâmetro de
que conecta
com
, e
com
, continuando ambos com a multiplicação pela derivada das funções de ativação dos neurônios. Também nota-se que nas derivadas, os termos são multiplicados pelos dados de entrada que acompanham os parâmetros derivados nos produtos escalares
e
.
Quadro 3. Derivadas parciais dos parâmetros de G e H
No Quadro 4, observa-se que o termo em comum nas derivadas parciais do neurônio
é a soma de duas expressões, uma que corresponde à conexão de
com
, e outra de
com
, definido na Equação 1. As expressões somadas incluem os termo vistos em
e
, com a multiplicação pelo parâmetro que conectam estes neurônios com
, seguido da multiplicação pela derivada da função de ativação dos mesmos. Analisando-se as derivadas parciais, percebe-se que este termo, assim como nos outros neurônios, é multiplicado pela entrada correspondente ao parâmetro derivado no produto escalar
.
Quadro 4. Derivadas parciais dos parâmetros de F
Equação 1. Termo em comum nas derivadas parciais F
Os termos destacados para cada neurônio são uma parte invariante de suas derivadas parciais, representando ajustes a serem aplicados neles como um todo, e por isso os denominamos como termos de erro dos neurônios. Assim, o erro do neurônio
é exibido no Quadro 5, onde também substituimos as expressões do erro pela variável
, nas derivadas parciais e na expressão do método
Gradient Descent
de
. Percebe-se que desta forma destacamos a presença dos dados de entrada do neurônio no cálculo do gradiente e na aplicação do método.
Quadro 5. Erro do neurônio I em suas derivadas parciais e no método Gradient Descent
Assim, para
,
e
, apresenta-se nos Quadros 6, 7 e 8, o erro destes neurônios e a substituição deles no método
Gradient Descent
.
Quadro 6. Aplicação do método Gradient Descent em G considerando o erro do neurônio
Quadro 7. Aplicação do método Gradient Descent em H considerando o erro do neurônio
Quadro 8. Aplicação do método Gradient Descent em F considerando o erro do neurônio
Na Imagem 2 exibe-se a disposição dos elementos que compõem os erros dos neurônios na rede. Observa-se que podemos escrever o erro de um neurônio utilizando o erro dos neurônios que o precede, como mostra-se no Quadro 9, salientando a influência ou propagação do erro entre os neurônios na etapa
backward pass
.
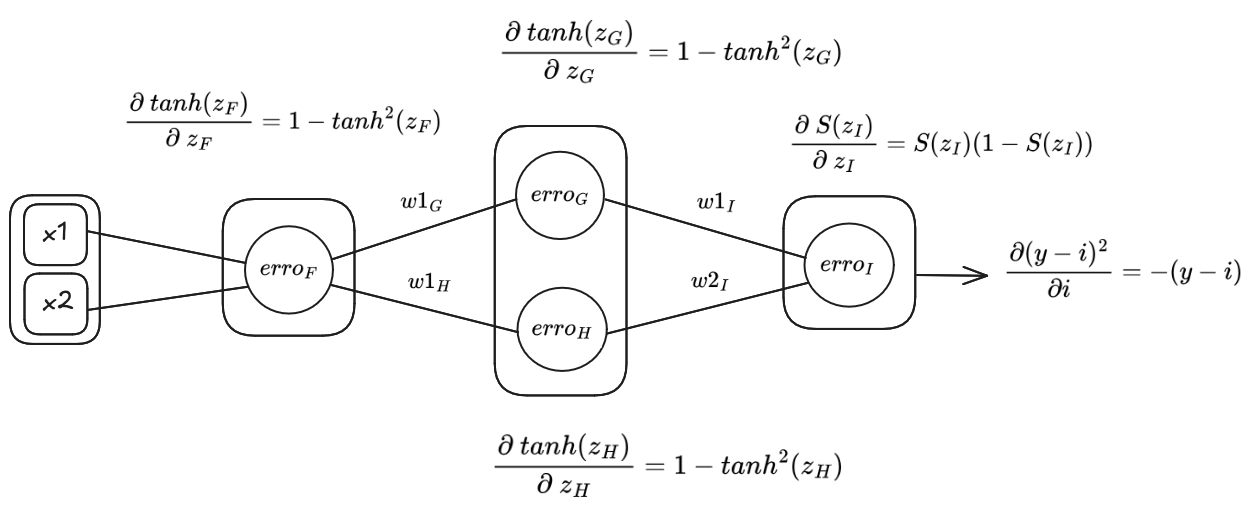
Imagem 2. Disposição dos elementos das expressões de erro dos neurônios na rede
Quadro 9. Equação do erro dos neurônios utilizando o erro dos neurônios anteriores
Treinamento de uma rede para solução da operação XOR
Em
Mais sobre o Perceptron e Bias, vimos que para solução da operação lógica XOR com uma rede neural, precisamos que ela tenha mais de um neurônio, fazendo-se necessário a implementação de uma estrutura para rede e o uso do algoritmo
Backpropagation
para treinamento. Com o conhecimento que adquirimos até o momento, podemos codificar uma rede capaz de usá-lo no processo de treinamento, bem como suportar mais de uma camada com mais de um neurônio e utilizar as funções de ativação Tangente e Logística.
Assim, primeiro podemos estabelecer como a implementação desta rede será utilizada. No Código 1 exibe-se a instanciação das classes
,
e
, criadas para abstração das funcionalidades da camada de entrada, camada oculta, e camada de saída, e uma classe própria da rede,
, que as conectam.
Erro ao copiar
input_layer = InputLayer(len_input=2)
num_hidden_layers = 1
list_hidden_layers = [HiddenLayer(num_neurons=2, act_function="tanh") for i in range(num_hidden_layers)]
output_layer = OutputLayer(num_neurons=1, act_function="logistic")
network = NeuralNetwork(input_layer=input_layer, hidden_layers=list_hidden_layers, output_layer=output_layer)Código 1. Instanciação das classes criadas para implementação da rede
No Código 2, mostra-se a classe
, que possui como atributo os valores e o número de elementos dos dados de entrada, e uma referência para próxima camada da rede. Na função
, conecta-se a camada de entrada com a próxima, e também inicializa-se os pesos de seus neurônios considerando o número de dados de entrada, para que tenhamos um número de pesos correspondente. Na função
, os dados são enviados para a camada seguinte através da chamada da função
da mesma com os dados.
Erro ao copiar
class InputLayer:
def __init__(self, len_input):
self.input = None
self.len_input = len_input
self.next_layer = None
def connect_to(self, layer):
self.next_layer = layer
for neuron in self.next_layer.list_neurons:
neuron.init_weights(self.len_input)
def process(self, input):
self.input = input
self.next_layer.process(self.input)Código 2. Classe InputLayer
No Código 3, apresenta-se a classe
para as camadas ocultas, que possui referências para as camadas anterior e seguinte, uma contagem dos neurônios, qual a função de ativação utilizada, e uma lista com as instâncias de neurônios,
, que possui. No Código 3.1, exibe-se a função
, que faz a conexão com a próxima camada em ambos sentidos e também inicializa os pesos dela de acordo com o número de neurônios que contém. Na função
, realiza-se o processamento da entrada da camada por cada neurônio, obtém-se os resultados, e os enviam para processamento na próxima camada.
Erro ao copiar
class HiddenLayer:
def __init__(self, num_neurons, act_function):
self.previous_layer = None
self.next_layer = None
self.num_neurons = num_neurons
self.act_function = act_function
self.list_neurons = [Neuron(act_function) for i in range(num_neurons)]Código 3. Classe HiddenLayer
Erro ao copiar
def connect_to(self, layer):
self.next_layer = layer
self.next_layer.previous_layer = self
for neuron in self.next_layer.list_neurons:
neuron.init_weights(self.num_neurons)
def process(self, input):
output = []
for neuron in self.list_neurons:
neuron.process(input)
output.append(neuron.output)
self.next_layer.process(output)Código 3.1. Funções connect_to e process de HiddenLayer
Em
também temos uma função
, exibida no Código 3.2, que faz a propagação do erro dos neurônios para próxima camada na etapa
backward pass
. Nisto, cada neurônio tem seus pesos atualizados de acordo com o
learning rate
e o valor de erro
, que varia conforme as conexões com as camadas anteriores. Observa-se que se a camada possui mais de um neurônio, enviamos a soma dos erros dos neurônios para camada seguinte, do mesmo modo que temos uma soma de expressões nas derivadas parciais de
, no Quadro 4.
Erro ao copiar
def update(self, learning_rate, prev_error):
prop_error = None
for i, neuron in enumerate(self.list_neurons):
error = neuron.update(learning_rate=learning_rate, prop_error=prev_error[i])
if prop_error is None:
prop_error = np.zeros(len(error))
prop_error += error
if self.previous_layer:
self.previous_layer.update(learning_rate, prop_error)Código 3.2. Função update de HiddenLayer
No Código 4 apresenta-se a classe
para camada de saída, que possui como atributo uma referência para camada anterior, seu número de neurônios, qual função de ativação utiliza, uma lista com as instâncias de seus neurônios, e o resultado da rede em
.
Erro ao copiar
class OutputLayer:
def __init__(self, num_neurons, act_function):
self.previous_layer = None
self.num_neurons = num_neurons
self.act_function = act_function
self.list_neurons = [Neuron(act_function) for i in range(num_neurons)]
self.output = NoneCódigo 4. Classe OutputLayer
No Código 4.1 exibe-se a função
da camada de saída, que limitamos para suportar apenas um neurônio, processando a entrada da camada de acordo com a função de ativação definida, provendo somente os resultados 1 ou -1, que são os dois valores que estamos usando como resultado da operação XOR. Nisto, para cada função de ativação determinamos um
threshold
para decisão do resultado, utilizando 0 na função Tangente e 0.5 na Logística, por serem os valores medianos do
contradomíniodessas funções, [1, -1] e [0, 1], respectivamente. A função
difere-se da que temos em
pela limitação de um neurônio e não termos um erro prévio, começando-se nela a propagação do erro com o resultado da derivada da função de erro,
, fazendo-se necessário o valor do resultado esperado
.
Erro ao copiar
def process(self, input):
if self.num_neurons == 1:
self.list_neurons[0].process(input)
if self.act_function == "tanh":
self.output = 1 if self.list_neurons[0].output >=0 else -1
elif self.act_function == "logistic":
self.output = 1 if self.list_neurons[0].output >=0.5 else -1
else:
raise Exception("Função de ativação não suportada me OutputLayer")
else:
raise Exception("Número de neurônios não suportado em OutputLayer")
def update(self, y, learning_rate):
error = self.list_neurons[0].update(learning_rate=learning_rate, y=y)
self.previous_layer.update(learning_rate, error)Código 4.1. Funções process e update de OutputLayer
No Código 5, apresenta-se a classe
para abstração de um neurônio. Como atributo temos a contagem e a lista dos pesos do neurônio, qual a última entrada que recebeu e seu respectivo resultado, e qual sua função de ativação. No Código 5.1, a função
inicializa os pesos do neurônio de acordo com um determinado número, considerando internamente a adição do
bias
. Na função
, temos o cálculo do produto escalar com a inserção do
na entrada, e cálculo da saída do neurônio de acordo com a função de ativação definida.
Erro ao copiar
class Neuron:
def __init__(self, act_function):
self.weights = []
self.num_weights = 0
self.input = None
self.output = None
self.act_function = act_functionCódigo 5. Classe Neuron
Erro ao copiar
def init_weights(self, num_weights):
self.num_weights = num_weights + 1 # inclusão do peso do bias
self.weights = np.random.uniform(-1, 1, self.num_weights)
def process(self, input):
self.input = np.insert(input, 0, 1) # inserção do bias
z = np.dot(self.input, self.weights)
if self.act_function == "tanh":
self.output = np.tanh(z)
elif self.act_function == "logistic":
self.output = 1.0 / (1.0 + np.exp(-z))Código 5.1. Funções init_weights e process de Neuron
No Código 5.2, exibe-se a função
de
, que faz o cálculo do erro e a atualização dos parâmetros do neurônio. Nela, determinamos que se não há um erro prévio, o neurônio está na camada de saída, começando-se a etapa
backward pass
com o cálculo da derivada da função de erro. Em sequência, para todo neurônio realizamos o cálculo da derivada da sua função de ativação e multiplicamos o resultado pelos pesos do neurônio para propagação do erro para próxima camada. Por fim, ajustamos os parâmetros considerando o erro calculado em
e os dados de entrada.
Erro ao copiar
def update(self, learning_rate, y=None, prop_error=0):
if prop_error == 0:
prop_error = -1 * (y - self.output) # mse'
if self.act_function == "tanh":
prop_error = prop_error * (1 - self.output**2) # mse' * tanh'
elif self.act_function == "logistic":
prop_error = prop_error * (self.output * (1 - self.output)) # mse' * S'
else:
raise Exception("Função de ativação não definida em Neuron")
error = self.weights * prop_error
self.weights -= learning_rate * prop_error * self.input
return errorCódigo 5.2. Função update de Neuron
No Código 6 apresenta-se a classe da rede
, que possui referências para todas camadas criadas, qual o número de camadas ocultas, o valor definido para
learning rate
, e um parâmetro
, que muda o modo de processamento da rede de treinamento para teste. No Código 6.1, temos a função
para inicialização da rede, conectando-se todas camadas com suas funções
. A função
é utilizada para indicar o começo da fase de testes, impedindo a rede de executar a etapa
backward pass
ao receber dados de entrada.
Erro ao copiar
class NeuralNetwork:
def __init__(self, input_layer, hidden_layers, output_layer):
self.input_layer = input_layer
self.num_hidden_layers = len(hidden_layers)
self.hidden_layers = hidden_layers
self.output_layer = output_layer
self.learning_rate = 0.1
self.is_inf_mode = FalseCódigo 6. Classe NeuralNetwork
Erro ao copiar
def init(self):
self.input_layer.connect_to(self.hidden_layers[0])
if len(self.hidden_layers) > 1:
for i in range(0, self.num_hidden_layers - 1):
self.hidden_layers[i].connect_to(self.hidden_layers[i + 1])
self.hidden_layers[self.num_hidden_layers - 1].connect_to(self.output_layer)
else:
self.hidden_layers[0].connect_to(self.output_layer)
def inf_mode(self):
self.is_inf_mode = TrueCódigo 6.1. Funções init e inf_mode de NeuralNetwork
No Código 6.2, temos a função
da rede que executa o algoritmo
Backpropagation
. Nela, se estamos no modo de teste, dado uma entrada apenas retornamos o resultado da camada de saída após a execução da etapa
forward pass
, e caso contrário, continuamos com a verificação da corretude da predição e execução da etapa
backward pass
se o resultado é diferente do esperado. Na função
, temos o início do processamento da rede através da camada de entrada e obtenção do resultado na camada de saída. Na função
, executa-se a função
da camada de saída, que começa a propagação do erro e ajuste dos parâmetros até a primeira camada oculta.
Erro ao copiar
def process(self, sample):
output = self.forward_pass(sample[:-1])
if self.is_inf_mode:
return output
y = sample[-1]
if output != y:
self.backward_pass(y)
return output
def forward_pass(self, input):
self.input_layer.process(input)
output = self.output_layer.output
if not output:
raise Exception("Nenhum resultado fornecido pela rede")
return output
def backward_pass(self, y):
self.output_layer.update(y, self.learning_rate)Código 6.2. Funções process, forward_pass e backward_pass de NeuralNetwork
Por fim, no Código 7 mostra-se a construção de uma rede para solução da operação XOR, onde criamos uma camada oculta com dois neurônios com a função Tangente, e uma camada de saída com um neurônio, com a função Logística. Em
https://gist.github.com/RenanGAS/9933eb1d275bb267a4c8ded4eb613a48, temos todos os códigos em um Jupyter Notebook.
Erro ao copiar
input_layer = InputLayer(len_input=2)
num_hidden_layers = 1
list_hidden_layers = [HiddenLayer(num_neurons=2, act_function="tanh") for i in range(num_hidden_layers)]
output_layer = OutputLayer(num_neurons=1, act_function="logistic")
network = NeuralNetwork(input_layer=input_layer, hidden_layers=list_hidden_layers, output_layer=output_layer)
network.init()
data = [[-1, -1, -1],
[-1, 1, 1],
[1, 1, -1],
[1, -1, 1]]
index_list = [0, 1, 2, 3]
epochs = 100
# Treinamento
for epoch in range(epochs):
correct_instances = 0
np.random.shuffle(index_list)
for index in index_list:
output = network.process(data[index])
if output == data[index][-1]:
correct_instances += 1
if correct_instances == len(data):
print(f"Sucesso")
break
# Teste
network.inf_mode()
for sample in data:
output = network.process(sample)
print(f"sample: {sample}")
print(f"output: {output}")Código 7. Treinamento e teste de uma rede neural para solução da operação XOR
Conclusão
Neste artigo vimos sobre as duas etapas do algoritmo
Backpropagation
, e o conceito de erro do neurônio em suas derivadas parciais. Também implementamos uma rede que suporta mais de uma camada oculta, bem como o uso de duas funções de ativação e a execução do algoritmo
Backpropagation
para treinamento. Como próximo passo, temos a elaboração de redes para predição de múltiplas classes e o uso do
dataset
MNIST.
Referências
- Ekman, M. Learning Deep Learning. Pearson Education, 2021.
- Contradomínio. Wikipedia, 2026. Disponível em: https://pt.wikipedia.org/wiki/Contradom%C3%ADnio.