Vanishing Gradients, Overfitting e o dataset MNIST [1/2]
24 de junho, 2026
Em
Predição de várias classes e o dataset MNIST, implementamos uma rede neural para classificação de dígitos no
dataset
MNIST
, e após vários experimentos modificando as camadas ocultas, não foi possível alcançar um desempenho satisfatório no conjunto de teste e identificamos o problema de
overfitting
. Quanto ao baixo desempenho obtido, em redes neurais existe o problema
vanishing gradients
, em que durante o processo de treinamento, os valores dos gradientes se aproximam de zero devido à saturação das funções de ativação, fazendo com que os parâmetros da rede fiquem estagnados. Sobre o
overfitting
, observamos um aumento do desempenho apenas no conjunto de treinamento ao longo das
epochs
, mostrando que a rede estava memorizando os dados ao invés de buscar uma solução geral para o problema de predição. Para superarmos estes obstáculos, temos uma série de técnicas para evitar a saturação das funções de ativação e métodos para impedir o sobreajuste dos parâmetros aos dados de treinamento.
Considerando a rede na Imagem 1, onde temos a função
squared error
como função de erro e as funções Tangente e Logística para os neurônios
e
, podemos observar o problema de
vanishing gradients
analisando o resultado da multiplicação
, que ocorre no início do cálculo do gradiente de cada neurônio. Considerando o gráfico da função Logística
na Imagem 2, dado que o resultado esperado da rede é 0 e obtemos em
um valor maior que
, entra-se em uma região saturada da função em que não há mais variações significativas do seu resultado, fazendo com que a derivada
seja próxima de 0, assim como o resultado de multiplicações subsequentes sobre ela.
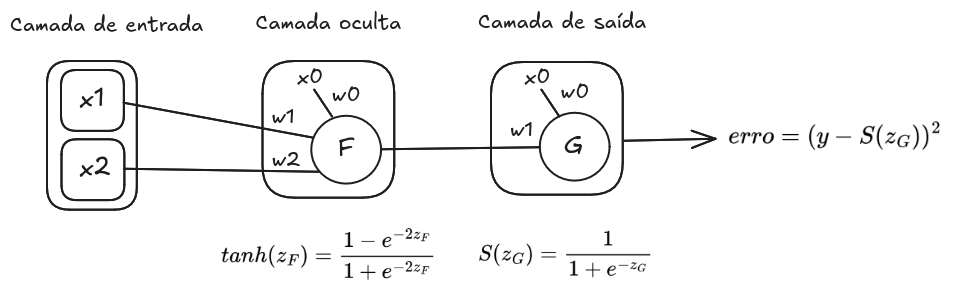
Imagem 1. Exemplo de uma rede neural
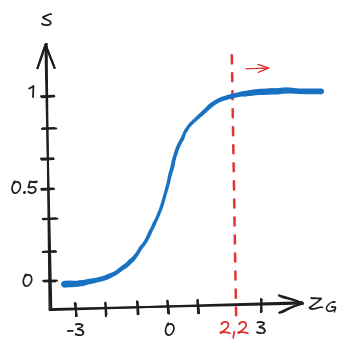
Imagem 2. Problema da função Logística no cálculo do gradiente
Desta forma, o valor do gradiente nessa região tende a zero, tendo-se que para resultados cada vez mais distantes do valor esperado, diminuimos a magnitude dos ajustes dos parâmetros ao invés de aumentá-los. Para visualizarmos isto, podemos resolver as derivadas
e
levando em conta o resultado esperado
, obtendo as expressões
e
, e multiplicá-las resultando em
, que expressa o comportamento do gradiente em função do resultado da função Logística. No Gráfico 1 exibe-se as funções
,
e
, considerando o contradomínio de
no intervalo [0, 1] no eixo
, destacando-se os resultados do gradiente na função
. Observamos que a partir do ponto
,
diminui conforme nos aproximamos de 1.
h(0.66) = 0.1481
f(S) = S
g(S) = S(1 - S)
h(S) = S² - S³
Gráfico 1. Visualização do comportamento do gradiente utilizando a função de erro squared error com a função Logística
Para solucionarmos este problema, podemos substituir a função
squared error
pela função
cross-entropy
, por sua multiplicação com a função Logística não causar esta diminuição do gradiente. No Quadro 1, apresenta-se a função
cross-entropy
como uma função de erro e sua respectiva derivada, ambas no contexto da Imagem 1.
Quadro 1. Função de erro cross-entropy e sua derivada
Considerando
,
resulta em
, e sua multiplicação pela derivada da função Logística segue como
. Assim, no Gráfico 2 troca-se
e
do Gráfico 1 por
e
, tendo-se em
uma função Identidade que cresce ao longo do intervalo e possui maior valor em
.
h(0.66) = 0.6600
f(S) = 1 / (1 - S)
g(S) = S(1 - S)
h(S) = S
Gráfico 2. Visualização do comportamento do gradiente utilizando a função de erro cross-entropy com a função Logística
De acordo com o tipo de predição, temos combinações de função de ativação e função de erro apropriadas na camada de saída. No caso da predição binária, em que há duas classes, utilizamos a combinação vista da função Logística com a função
cross-entropy
, para predição de números escalares usamos a função Identidade com a função
squared error
, e para predição de
classes aplicamos a função
softmax
com a função
categorical cross-entropy
, ambas variações das funções Logística e
cross-entropy
para suporte de várias classes.
No Quadro 2, apresenta-se a expressão da função
categorical cross-entropy
como função de erro, e a função de ativação
softmax
. Em
é feito o somatório do produto
para cada classe
, onde
e
são os resultados esperado e obtido pela rede para a classe. Em
, temos que o resultado da função de ativação de cada neurônio
é a porcentagem do seu fator
em relação ao somatório
, que inclui todos neurônios da camada de saída, fazendo com que a soma dos resultados seja igual a 1. Deste modo, cada neurônio pode ser utilizado para indicar a probabilidade de uma determinada instância para cada classe.
Quadro 2. Função de erro categorical cross-entropy e a função de ativação softmax
Nas camadas ocultas também pode-se gerar o problema de
vanishing gradients
pela função Tangente ter um formato semelhante ao da função Logística. Considerando a rede da Imagem 1, na Imagem 3 podemos observar que se
é maior que
ou menor que
, a derivada de
é próxima de 0, e por ela estar incluída no cálculo do gradiente do neurônio
, impede a continuação do ajuste de seus parâmetros.
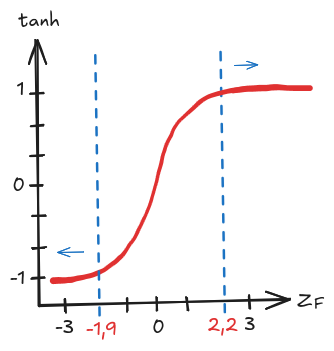
Imagem 3. Problema da função Tangente no cálculo do gradiente
Como solução, temos o uso da função ReLU (
rectified linear unit
), exibida na Imagem 4, como função de ativação nas camadas ocultas. Nota-se que ela não é diferenciável em
, e por isto utiliza-se uma exceção para definição de sua derivada, tendo-se que para
a derivada é igual a 1, considerando também o fato de que para
a função ReLU é uma função Identidade com variação constante. Por seu resultado ser igual a 0 para
, ela se enquadra como uma função não linear, sendo útil para o processo de aprendizado da rede.
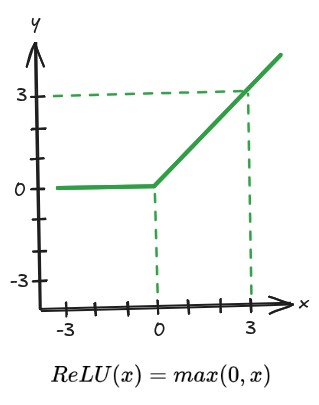
Imagem 4. Função de ativação ReLU
A função ReLU tem um custo computacional menor do que a função Tangente, e por sua derivada ser igual a 1 para
, não provoca o problema de
vanishing gradients
. A consequência do seu resultado e derivada ser igual a 0 para
, é de que os neurônios podem não ser utilizados pela rede, criando
dead neurons
. Isto é considerado uma capacidade que pode trazer benefícios à rede, mas como também há chances de uma invalidação em massa de neurônios, temos métodos de inicialização de parâmetros para controlar o uso da função, e variações da função ReLU como a função Leaky ReLU, apresentada na Imagem 5, que altera seu comportamento para
.
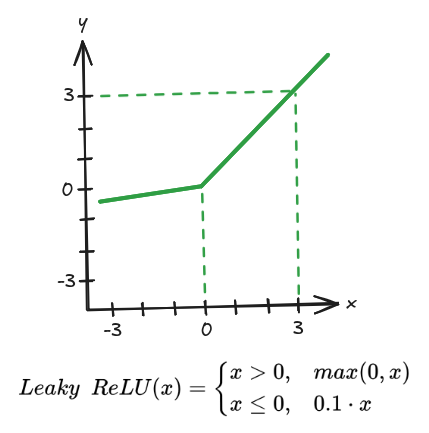
Imagem 5. Função de ativação Leaky ReLU
Outra forma de lidar com
vanishing gradients
é através do tratamento dos dados recebidos pelas funções de ativação. Considerando uma rede que tem como entrada um conjunto numérico no intervalo [0, 255], por causa do tamanho considerável do intervalo e por ser composto apenas de números positivos, os produtos escalares
recebidos pelas funções na primeira camada oculta podem ser números grandes positivos ou negativos, fazendo com que tenhamos resultados extremos para funções Tangente ou ReLU. No caso das funções Tangente temos o problema de
vanishing gradients
, e nas funções ReLU podemos ter resultados nulos que podem causar a perda de neurônios, ou resultados de grandeza igual a
, visto que para
positivo a função ReLU é uma função Identidade, causando o problema chamado
exploding gradients
, onde por causa desta extrapolação dos resultados temos gradientes com valores muito grandes, prejudicando o treinamento da rede.
Assim, costuma-se realizar a padronização dos dados de entrada através da fórmula exibida na Equação 1, em que centralizamos os valores em 0 com a subtração pela média e divisão pelo desvio padrão dos dados. Desta forma diminui-se o tamanho do intervalo numérico e as chances de obtermos produtos escalares altos. Destaca-se que no contexto de treinamento e teste de uma rede neural, o cálculo da média e desvio padrão é feito com base nos dados do conjunto de treinamento, e estes valores são utilizados para padronização do conjunto de teste, para não testarmos o modelo sobre dados modificados com informações que não fazem parte do treino.
Equação 1. Fórmula para padronização de dados
Com o tratamento dos dados de entrada, para manutenção dos dados que irão circular nas camadas ocultas temos a técnica
batch normalization
. Ela consiste de duas etapas, apresentadas no Quadro 3, sendo a primeira uma fórmula para padronização dos dados e a segunda uma operação para que a rede controle a representação final dos mesmos.
Quadro 3. Etapas da técnica batch normalization
A técnica considera que o treinamento da rede é feito em
batches
, ou seja, processa-se
instâncias paralelamente para atualização dos parâmetros da rede de acordo com o valor médio do gradiente. Assim, considerando que
é uma lista de
valores
produzidos pelos neurônios de uma camada para uma instância
, na primeira etapa primeiro é feito o cálculo da lista de médias
e lista de quadrados de desvio padrão
, com os resultados
das
instâncias. Em seguida, padroniza-se cada
obtendo-se
, que na segunda etapa segue multiplicado por
e somado com
, resultando em
, constituindo a série de valores que serão fornecidos para as funções de ativação da camada com respeito à instância
. Ambas variáveis
e
são inseridas pela técnica como parâmetros na rede, permitindo que haja um processamento de dados interno em favor da minimização da função de erro.
Outros fatores que influenciam os valores de entrada das funções de ativação são os parâmetros dos neurônios, e por isso temos métodos para inicializá-los como
e
. O método
glorot initializationsurgiu como um método de inicialização para melhorar o desempenho de redes neurais, considerando o fato de que uma inicialização tradicional, exibida na Equação 2, tinha um desempenho inferior a uma inicialização obtida a partir de um modelo de Aprendizado Não-supervisionado. Disto, propuseram o método exibido na Equação 3, onde os pesos da próxima camada
são obtidos considerando os parâmetros
e
, que são, respectivamente, o tamanho da camada corrente
e da camada a ser inicializada
. Como resultado, o método mostrou-se capaz de controlar a variância dos resultados das funções de ativação e dos gradientes nas camadas ocultas, tendo melhores desempenhos do que a inicialização convencional em
datasets
como Shapeset-3x2 e MNIST.
Equação 2. Inicialização de parâmetros a partir de uma distribuição uniforme, considerando como parâmetro o tamanho n da camada anterior
Equação 3. Glorot initialization
O método
he initializationfoi proposto como um método de inicialização para neurônios que utilizam a função ReLU, destacando-se no artigo que esta função apresenta um desempenho superior comparado às funções do tipo sigmoid, como a função Tangente, e que o método
é limitado a estas funções. Nisto, junto com o método, exibido na Equação 4, também propõe-se uma generalização da função ReLU, chamada
Parametric ReLU
(PReLU), exibida na Equação 5. O método inicializa os parâmetros a partir de uma distribuição normal e utiliza o tamanho da camada anterior
, e a função PReLU generaliza a região negativa da função ReLU com um parâmetro
. A combinação do método com a função PReLU gerou resultados superiores aos dos vencedores da competição ILSVRC 2014, para modelos de classificação de imagens no conjunto ImageNet 2012, ultrapassando também o desempenho humano no desafio.
Equação 4. He initialization
Equação 5. Função PReLU
Para tratar o problema de
overfitting
, temos três técnicas chamadas
early stopping
,
weight decay
e
dropout
. A técnica
early stopping
consiste do uso do melhor estado da rede durante as
epochs
de treinamento. Para isto, armazena-se seus parâmetros a cada
epoch
, e ao final do treinamento é feito a análise do erro sobre os dados de treino e teste. Nisto, se o erro no conjunto de teste começa a crescer após um período de decréscimo, tendo um formato em "U", e o erro no conjunto de treino permanece decrescendo, define-se que na
epoch
anterior ao crescimento do erro a rede estava em sua melhor condição, antes de ocorrer o
overfitting
, sendo o estado mais apropriado para uso.
A técnica
weight decay
trata-se da punição de parâmetros que possuem uma magnitude significativa por causa de instâncias específicas do conjunto de treinamento, prejudicando a generalização da rede. Disto, nela propõe-se uma soma da magnitude dos pesos diretamente no cálculo do erro, e o controle da intensidade da penalidade através de um parâmetro
. Em específico, temos o algoritmo
L1 regularization
que adiciona à função de erro o somatório de todos pesos da rede, e sua variação
L2 regularization
, que faz o somatório do quadrado dos pesos, ambos exibidos na Quadro 4.
Quadro 4. Regularização L1 e L2
Por último, a técnica
dropoutconsiste da desativação de uma porção aleatória dos neurônios de uma camada a cada
epoch
de treinamento. A técnica tem o objetivo de fazer com que todos neurônios aprendam características relevantes dos dados, treinando combinações de partes distintas da rede sobre todo conjunto. Nisto, busca-se também evitar a criação de interdependências negativas entre os neurônios de uma camada ou camadas diferentes, como alguns neurônios com responsabilidades pouco importantes por causa de outros com maior destaque. Na aplicação da técnica, em cada camada definimos uma porcentagem
de neurônios para serem desconsiderados nas
epochs
.
Conclusão
Neste artigo vimos sobre os problemas de
vanishing gradients
e
overfitting
, introduzindo a função
cross-entropy
como função de erro, a combinação das funções
softmax
e
categorical cross-entropy
para predição de múltiplas classes, e o uso da função ReLU nas camadas ocultas. Também estudamos sobre a padronização de dados, a técnica
batch normalization
, e os métodos de inicialização
glorot initialization
e
he initialization
, para evitar a saturação das funções de ativação. Por último, vimos as técnicas
early stopping
,
weight decay
e
dropout
, que fazem, respectivamente, a análise do erro da rede, a punição de parâmetros, e o treinamento de combinações distintas de neurônios para tratar o
overfitting
. Como próximo passo, temos a aplicação dessas técnicas para obtermos melhores resultados no
dataset
MNIST.
Referências
- Ekman, M. Learning Deep Learning. Pearson Education, 2021.
- MNIST database. Wikipedia, 2026. Disponível em: https://en.wikipedia.org/wiki/MNIST_database.
- Xavier Glorot, Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. PMLR, 2010. Disponível em: https://proceedings.mlr.press/v9/glorot10a.html.
- Kaiming He et al. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv, 2015. Disponível em: https://arxiv.org/abs/1502.01852.
- Nitish Srivastava et al. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. PMLR, 2014. Disponível em: https://jmlr.org/papers/v15/srivastava14a.html.